 Table Input
Table Input
Getting Started: Generate a Basic SQL Query
You can auto-generate a query using the Get SQL select statement button.
This opens the database explorer, allowing you to select a table or view. Once selected, you can choose to generate:
-
A full column list:
SELECT col_a, col_b, col_c FROM my_table; -
A wildcard query:
SELECT * FROM my_table;
Use Fields from a Previous Transform
To pass dynamic values into your SQL query at runtime, use the Insert data from transform option. This creates a JDBC Prepared Statement using ? placeholders.
Use ? in your SQL where values from the input transform should be inserted. Values are passed in the order of fields in the incoming stream. Use a Select Values transform to ensure the correct field order.
Prepared statements:
-
Improve security by preventing SQL injection
-
Cannot parameterize all parts of a SQL statement (e.g.,
IN (?)or table names)
You can also combine this with variable substitution.
Examples
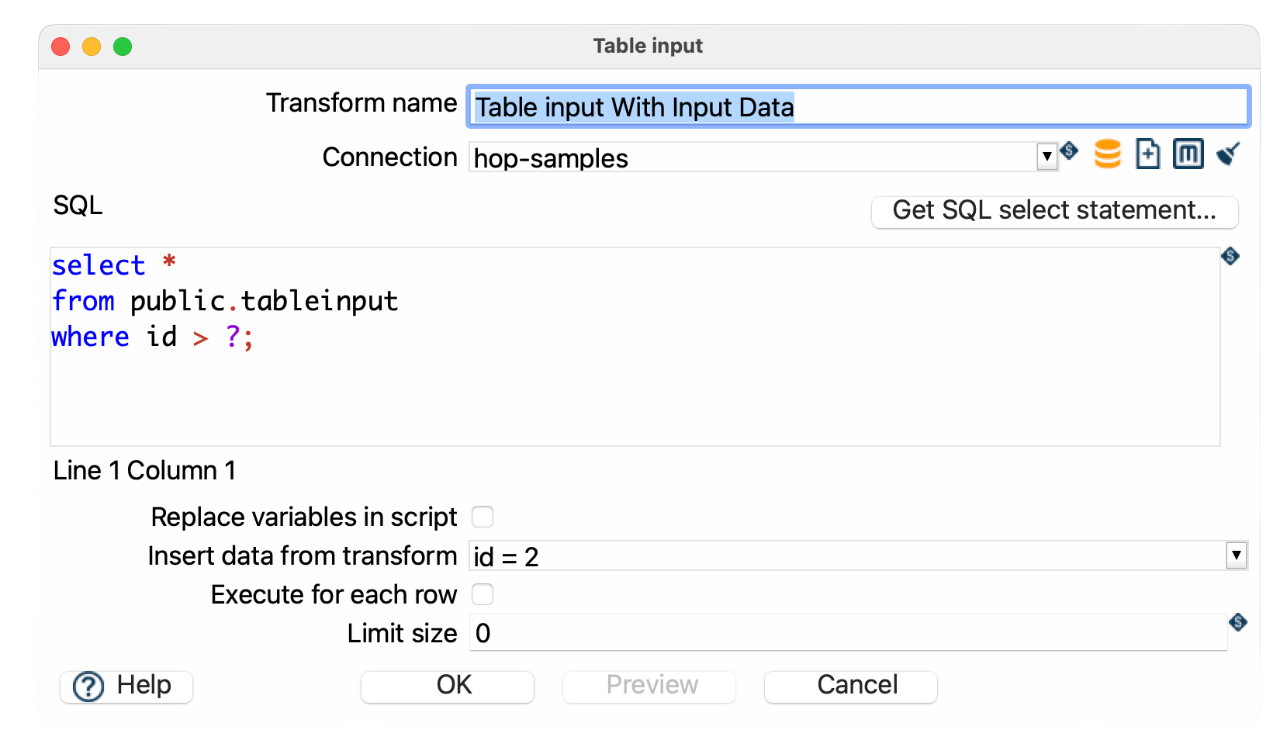
SELECT *
FROM public.tableinput
WHERE id > ?;-
Replace variables in script: unchecked
-
Insert data from transform: Select the previous transform providing NameId and AddressId
Sample pipeline: tableinput-accept-input.hpl
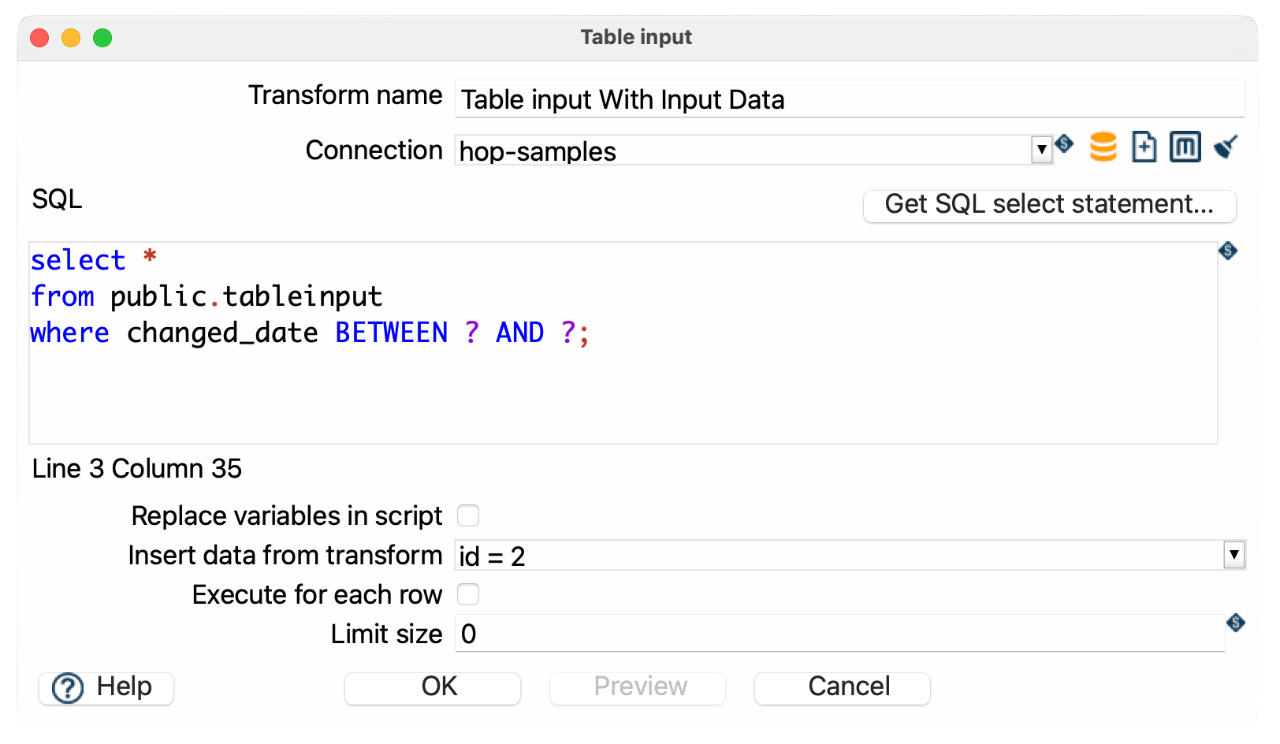
SELECT *
FROM public.tableinput
WHERE changed_date BETWEEN ? AND ?;-
Use a
Get System Infotransform to generate the start and end dates -
Insert those dates using
Insert data from transform
Use Variables in Your SQL Query

If your query includes Hop variables, enable Replace variables in script. This performs a simple string replacement before the query is sent to the database.
SELECT *
FROM public.tableinput
WHERE id > {openvar}PRM_ID{closevar};-
${PRM_ID}is defined as a pipeline variable (e.g., via parameters orSet Variablestransform)

-
This gives you full control over the query structure
-
Combine with
?placeholders if needed
| Variable substitution happens before execution and does not protect against SQL injection. |
-
Replace variables in script: checked
-
Insert data from transform: leave empty
Sample pipeline: tableinput-variables.hpl
Using Both Variables and Prepared Statements
You can combine both techniques in a single query:
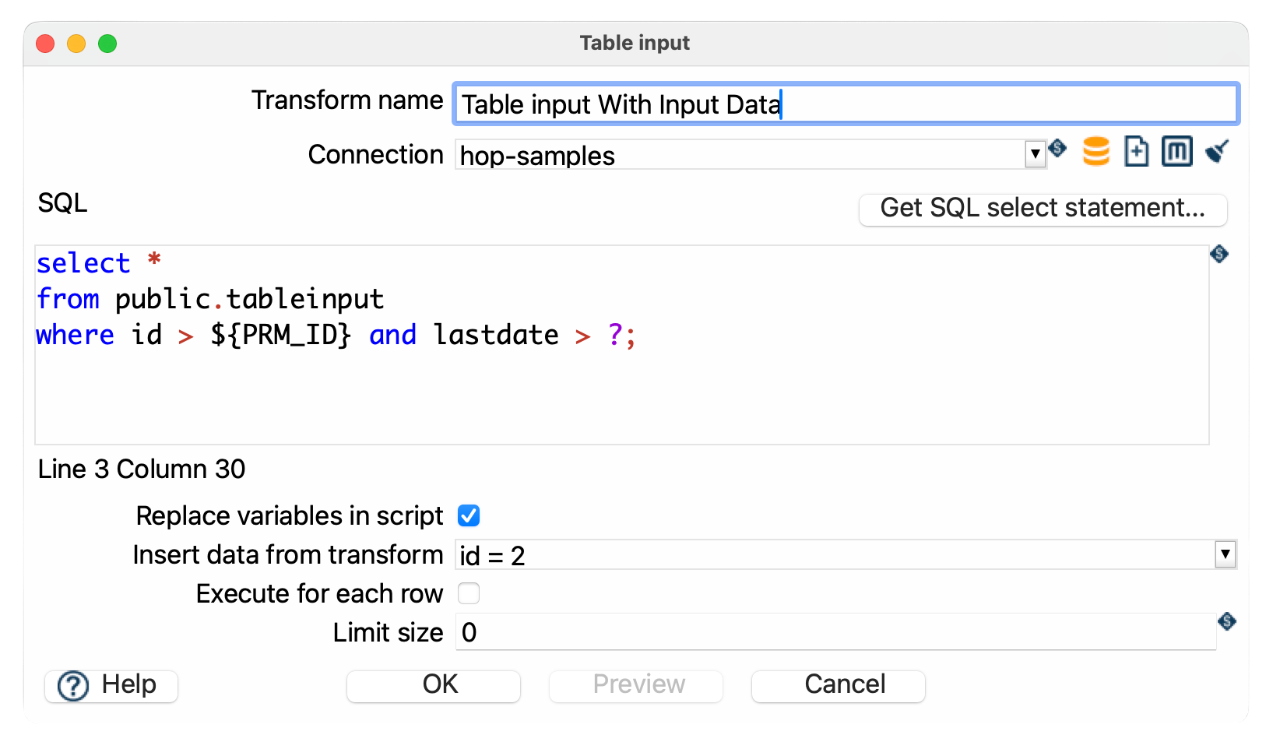
SELECT *
FROM public.tableinput
where id > {openvar}PRM_ID{closevar} AND lastdate > ?;-
${startDate}is a pipeline variable -
?is a parameter provided by the input stream
Pro Tips
| The Table input transform does not pass input data to the output, only fields inside the query are returned to the pipeline so all other variables and data will be lost. You can solve this by adding the variable as a field in the query or put a Get variables transform behind the table input. |
| If you are getting unexpected query results, try clearing the database cache. Click the broom icon or go to Tools > Clear DB Cache. After clearing, click OK, save your pipeline, and reopen it if needed. |
| A cartesian join transform will combine a different number of fields from multiple table inputs without requiring key join fields. |
| Using the "insert data from transform" drop down will block until the transform selected has completed. |
For better performance with large datasets you can use indexed columns in WHERE clauses and avoid SELECT * and only retrieve needed fields. |
Dynamic SQL with Metadata Injection
Table Input can be used in a metadata-driven pipeline. For example, create a template pipeline with a generic query:
SELECT *
FROM {openvar}tableName{closevar}
WHERE {openvar}condition{closevar}Then use a Metadata Injection transform to inject actual values (e.g., from a CSV or database).
-
Create a template pipeline with Table Input
-
Use
${tableName}and${condition}as placeholders -
In a separate pipeline, use Metadata Injection to inject values into the SQL field
-
Execute the injected pipeline
This allows you to create reusable and dynamic pipelines without editing SQL manually.
You can inject metadata into the following fields of the Table Input transform:
-
Connection
-
SQL
-
Replace variables in script?
-
Insert data from transform
-
Execute for each row?
-
Limit size
Preview
The Preview button opens a dialog where you set how many rows to fetch and a query timeout in seconds (JDBC Statement#setQueryTimeout).
-
The timeout applies only while the pipeline is running in preview mode from the Hop GUI (not during a normal pipeline run from a run configuration or Hop Run).
-
You can set a default for the timeout field with the
HOP_QUERY_PREVIEW_TIMEOUTapplication variable (0= no default from the variable). When the variable is0or unset, the dialog still suggests5seconds for the initial value.
Options
| Option | Description |
|---|---|
Transform name | Name of the transform instance. |
Connection | Database connection to execute the query against. |
SQL | SQL statement used to retrieve data. Use |
Replace variables in script? | Enable to substitute variables (e.g., |
Insert data from transform | Select a transform to use its fields as input for |
Execute for each row? | Runs the SQL query once for each incoming row, using that row’s values as parameters. Only applies when “Insert data from transform” is enabled. Useful for row-specific lookups, but may be slower on large datasets. |
Limit size | Number of rows to return. |