Working with Neo4j data
Using examples, this article explains how to get started with loading data into Neo4j and then getting it back out if needed.
Introduction
A graph is made up of nodes and relationships (also called edges). Relationships link up Nodes and both can have any number of properties. In that regard a graph is different from your typical 'relational database' which hints at the typical challenge when loading data into Neo4j and getting it back out: converting between relational and graph data. In this document we’ll sketch some possibilities to get started.
Samples setup
To make the Neo4j examples work in the neo4j/ folder of your samples project you need to configure a few variables:
-
NEO4J_HOSTNAME : The Neo4j server hostname
-
NEO4J_PORT : The neo4j database port (default is 7687)
-
NEO4J_USERNAME : The username
-
NEO4J_PASSWORD : The password
These variables can be easily set by creating a new environment which represents your situation. Create a new environment configuration file and set the variables in there.
Updating graphs
Graph Output : The beers Wikipedia example
The Graph Output transform is a useful transform which is capable of updating multiple nodes and relationships at the same time. To get started with this transform you can take a look at workflow neo4j/beers-wikipedia-graph.hwf.
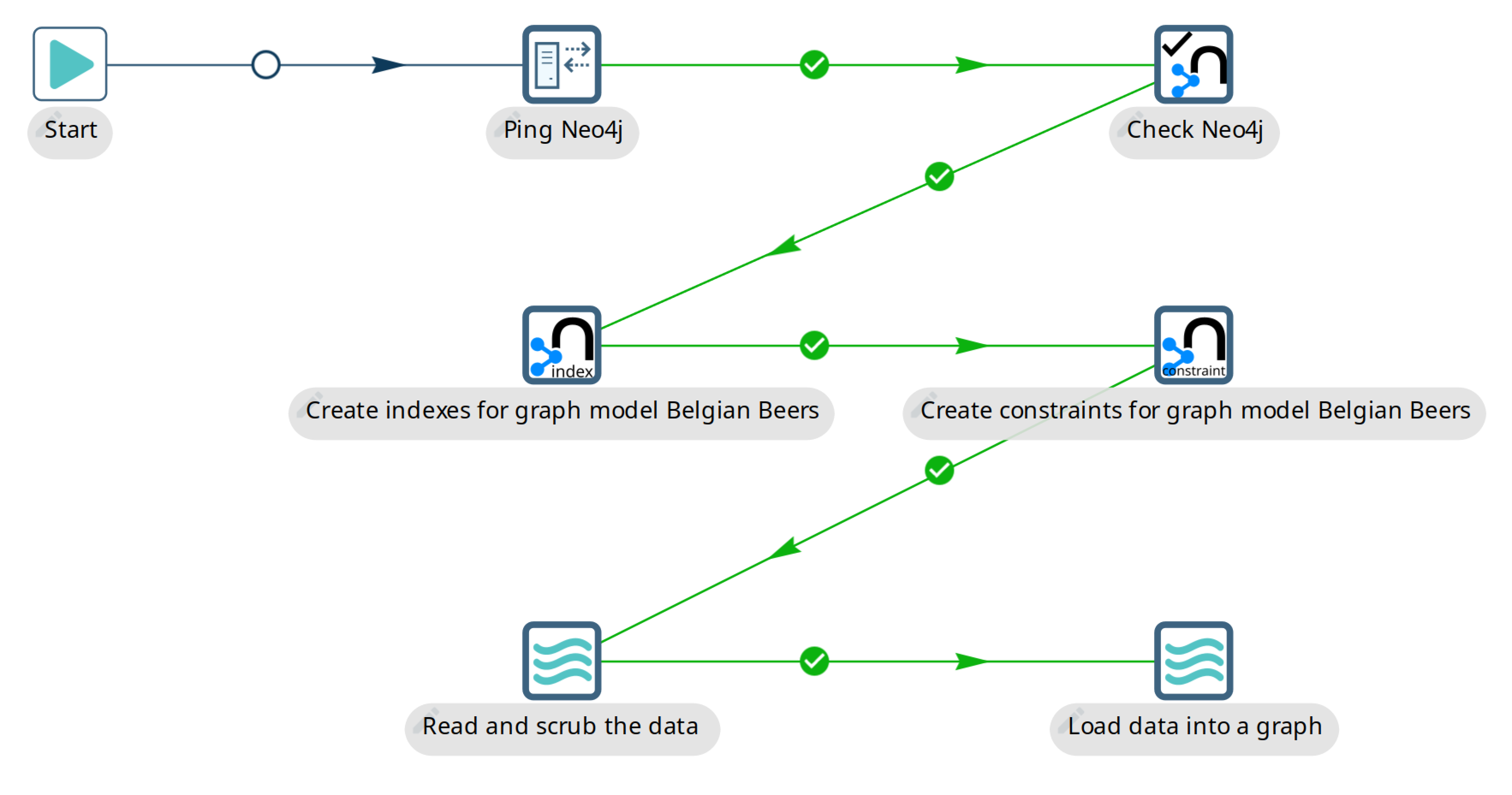
This workflow takes the following actions:
-
Ping Neo4j: Perform a network ping to the Neo4j server to see if it’s reachable.
-
Check Neo4j: connect to the Neo4j server and returns a static value from it to see if it’s working as expected
-
Create indexes for graph model Belgian Beers: Create indexes to get great performance when updating nodes or relationships
-
Create constraints for graph model Belgian Beers: Create constraints to guarantee uniqueness of primary key properties
-
Read and scrub the data: Load the raw HTML from wikipedia containing a table with Belgian Beers information. This information is scrubbed (cleaned up) and translated to English.
-
Load data into a graph: Data is loaded into Neo4j using the
Belgian Beersgraph model and a field-to-graph mapping.
The way that data is mapped to a graph model is quite simple. Take the Graph Output transform in the data loading pipeline:
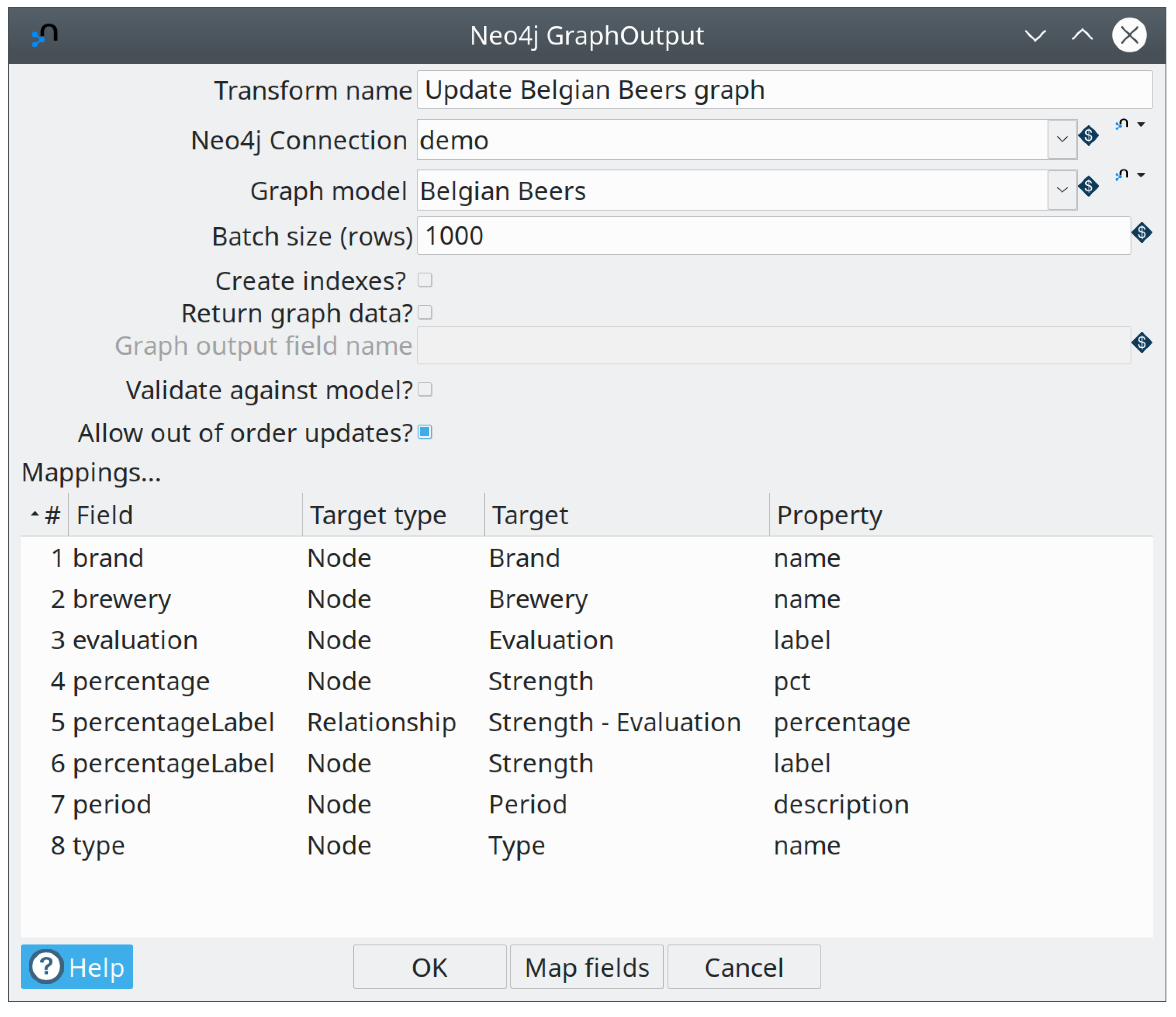
As you can see above this transform doesn’t require any technical knowledge. You can use the "Map fields" button to use a GUI to map the input fields on the left with the various node and relationship properties in your graph model. You can also do this manually.
Neo4j Output : parallel data loading
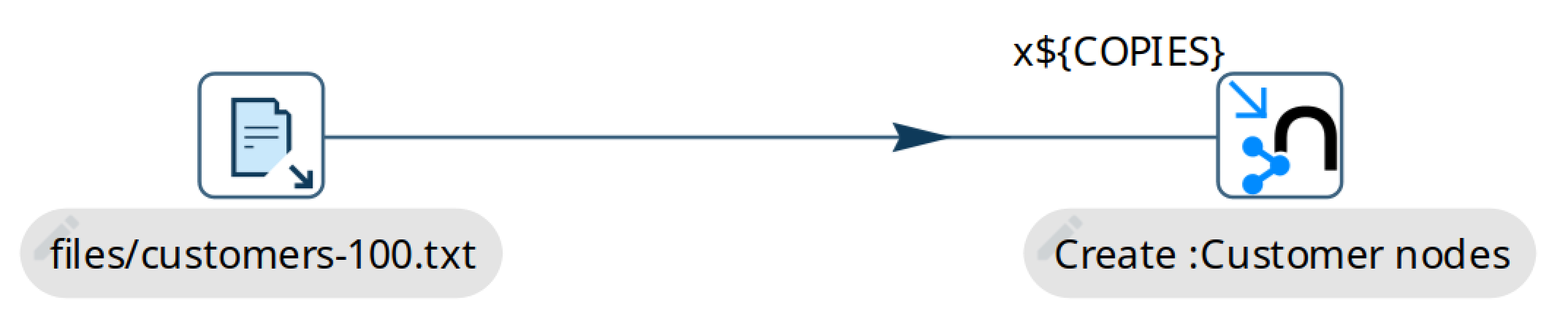
The Neo4j Output transform is useful for simple data loading into one node, two nodes and/or a relationship. It doesn’t require any knowledge of Cypher to use. Take a look at workflow neo4j/neo4j-output-parallel-load.hpl:
In this particular example we simply map the fields into the properties of a single node so we can use the Neo4j Output transform instead of Graph Output described above. The advantage is in this case that we have a simpler mapping and can potentially load data faster.
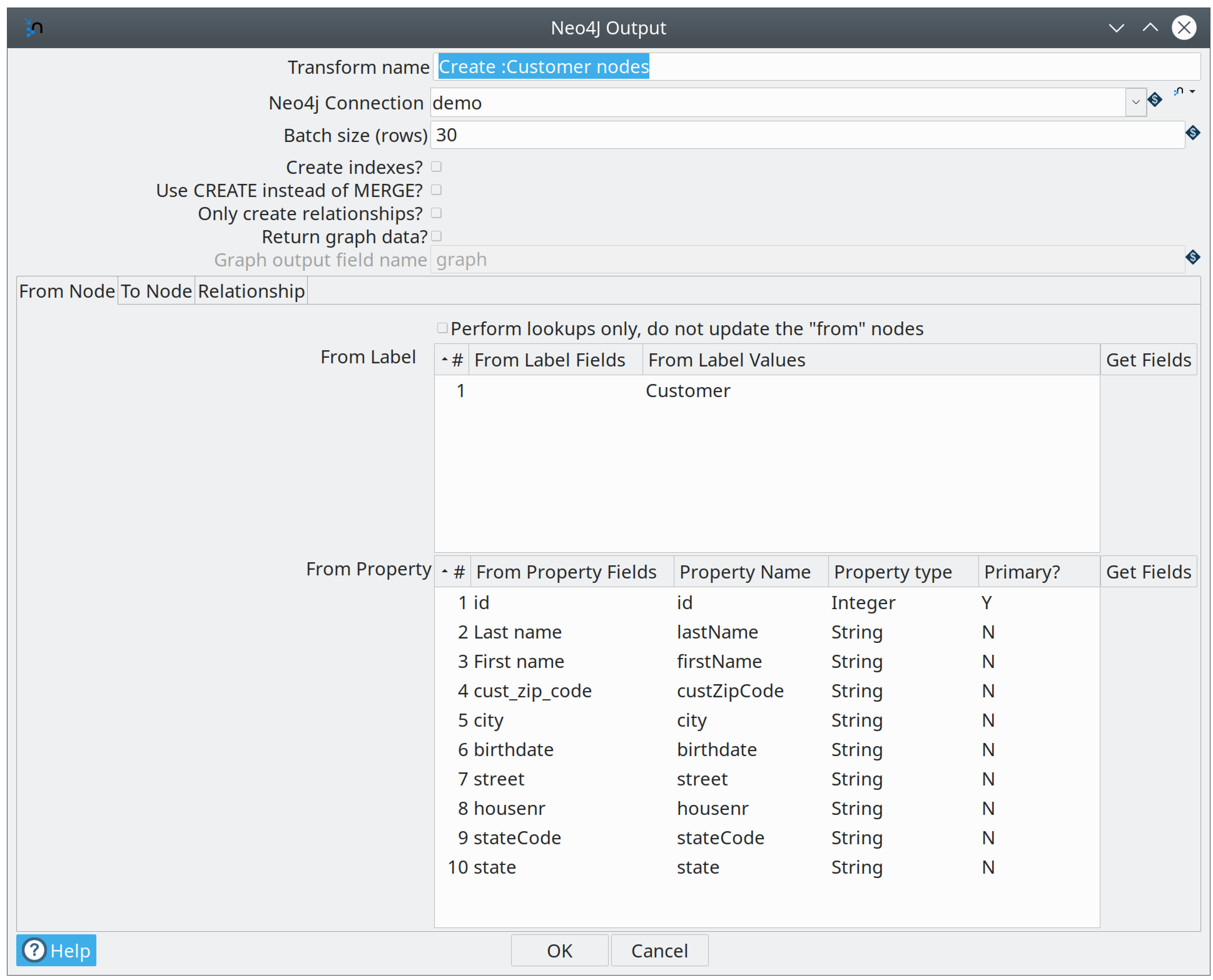
There is also no need for a graph model so this transform is great to handle simple scenarios very quickly without any fuss. What this sample also showcases is that you can load larger data sets in parallel. In fact this pipeline has a parameter called COPIES set to 4 by default which will load into Neo4j in 4 different threads in parallel.
Cypher : a simple unwind example
The Neo4j Cypher transform is the Swiss army knife in our Neo4j toolbox. It’s capable of doing pretty much everything Neo4j related if you have knowledge of Cypher. In example neo4j/neo4j-cypher-unwind-simple.hpl:
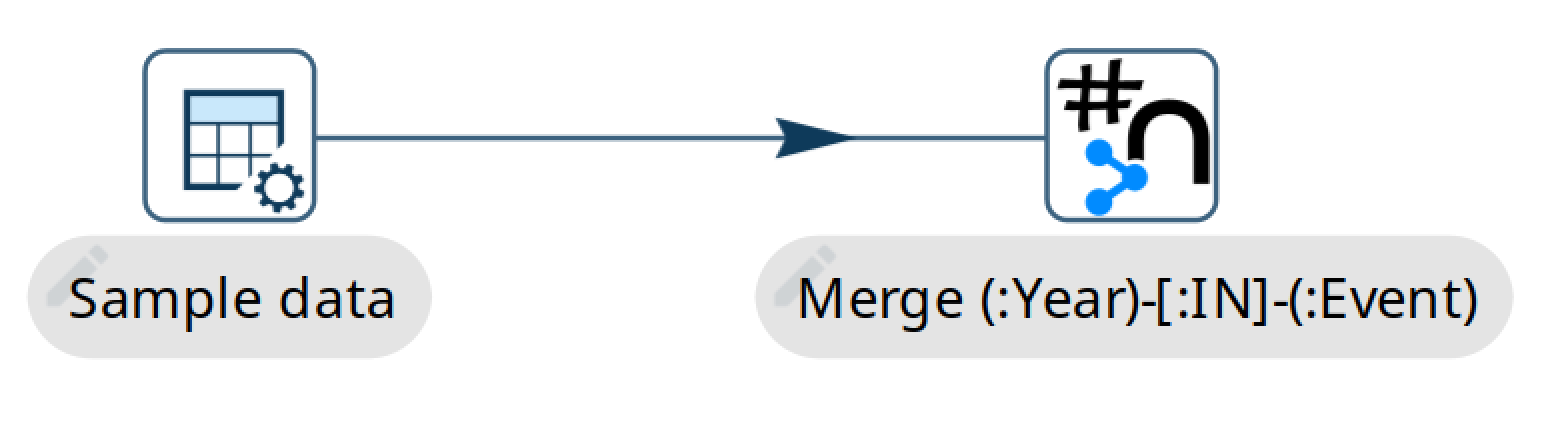
In this particular example we always use the same Cypher statement. This allows us to group input data so we can use an UNWIND command which will dramatically speed up the performance. It’s a step up from batching different commands together.
The first thing we need to do is collect all the input rows (mapped to parameter values) into a values map (on the Options tab):

The parameters you want to pass to the Cypher statement are listed on the Parameters tab. Finally, we can construct the Cypher statement itself:
UNWIND $events AS event
MERGE (y:Year { year: event.year })
MERGE (y)<-[:IN]-(e:Event { id: event.id })
RETURN e.id AS x
ORDER BY xRemoving data : The Cleanup example
Sometimes you might want to remove sets of data from Neo4j or indeed everything, for example during testing (see the Neo4j integration tests of the Hop project for examples). The included example is called neo4j/cleanup-remove-everything.hwf
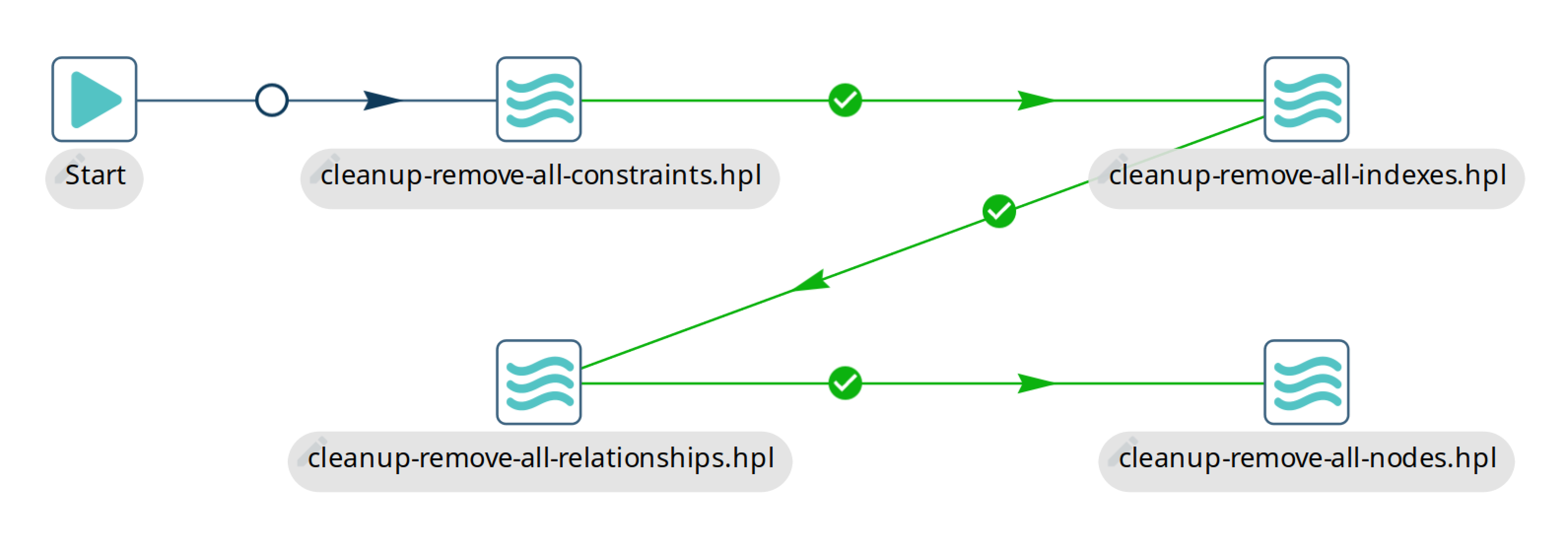
The way indexes and constraints are removed is by calling db.indexes() or db.constraints() and by iterating over those values to remove all of them. Nodes and relationships are deleted in batches to reduce the strain on the Neo4j database transaction handler. That handler might have a hard time deleting very large amounts of nodes or relationships because Neo4j is an ACID compliant database.
Retrieving data
Cypher : complex returns
As mentioned above, the Neo4j Cypher transform can not only be used to load data but also to retrieve it. Example pipeline neo4j/neo4j-cypher-complex-returns.hpl shows how to return complex data types like List, Map and Node from a Neo4j graph:

The way this happens is that Node, Relationship and Path values can be mapped to Hop Graph or String (in JSON format) output fields. Neo4j List and Map data types are always converted to String fields in JSON format. Those can then be processed further in the rest of the pipeline.
Bulk loading
Sometimes we want to load years of historical data before we start updating our graph. In this case we can use the tool neo4j-admin import. This tool is designed to be very fast in bulk loading large amounts of data into a new graph database. It works by loading CSV files which are expected to be in a particular format to describe the various nodes and relationships in a graph.
To help out with imports we have a number of tools at your disposal:
-
The Graph data type: transforms Neo4j Output and Neo4j Graph Output have options to write their output to a field of type
Graph. These transforms are capable of flagging the primary key field of nodes which encapsulates enough information to generate CSV files with… -
Neo4j Split Graph : With this transform we can split up the multiple nodes and relationships stored in a single Graph field produced by the Graph Output transform. You can then filter out particular nodes or relationships to guarantee uniqueness or other post processing.
-
Neo4j Generate CSVs : this transform will help you with the creation of the CSV files for import.
-
Neo4j Import : this transform will generate the
neo4j-admin importstatement for you and execute it. It uses the list of CSV files and their types (node/relationship) to do this as well as the options you selected in the transform dialog.