Running the Apache Beam samples With Apache Spark
Prerequisites
Check the prerequisites to make sure you have the correct java version, have built your Apache Hop fact jar and have exported your project metadata to a JSON file.
Get Spark
Check the Supported Versions on the Getting Started With Beam page to find the latest supported Spark version for your Hop version.
For example, for Hop 2.7, the latest currently supported version is 3.4.x.
Download your selected Spark version and unzip to a convenient location.

Start your local Spark single node cluster
To keep things as simple as possible, we’ll run a local single node Spark cluster.
First we need to start our local master. This can be done with a single command from the folder where you unzipped Spark:
run <SPARK_FOLDER>/sbin/start-master.sh.
Your output should look similar to the one below:
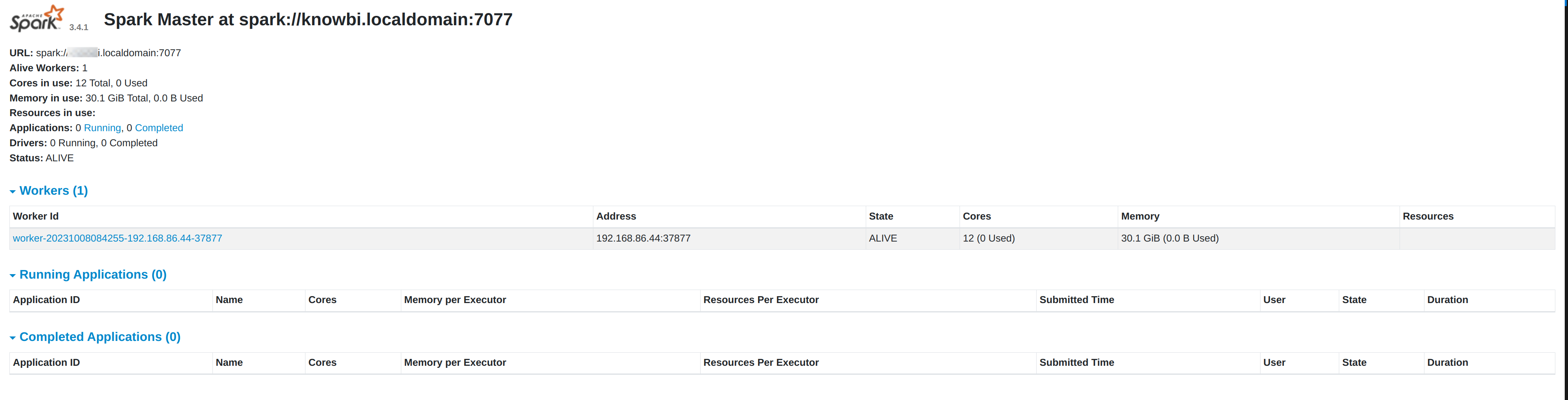
starting org.apache.spark.deploy.master.Master, logging to <PATH>/spark-3.1.2-bin-hadoop3.2/logs/spark-<USER>-org.apache.spark.deploy.master.Master-1-<HOSTNAME>.outYou should now be able to access the Spark Master’s web ui at http://localhost:8080.
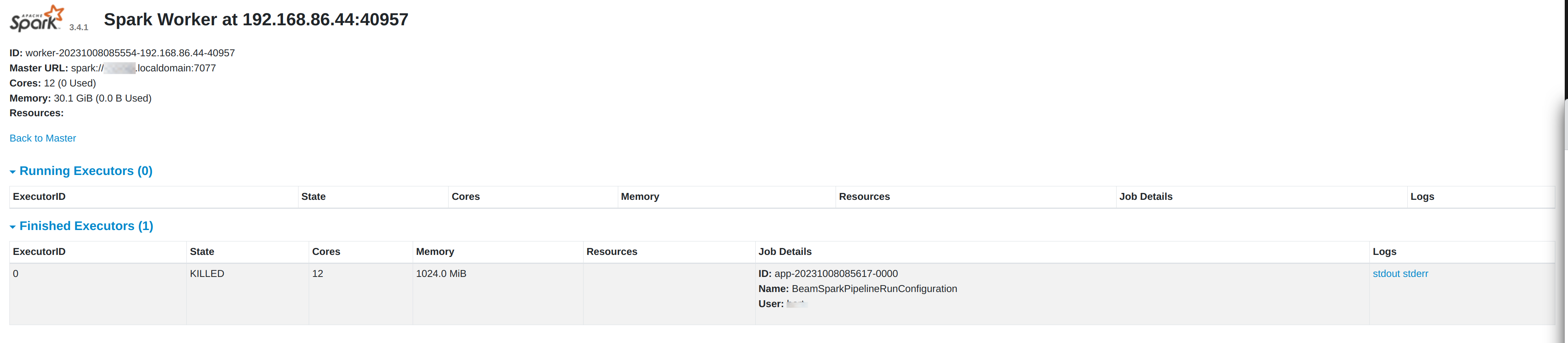
Copy the master’s url from the master’s page header, e.g. spark://<YOUR_HOSTNAME>.localdomain:7077.
With the master in place, we can start a worker (formerly called slave). Similar to the master, this is a single command that takes the master’s url that yo
sbin/start-worker.sh spark://<YOUR_HOSTNAME>.localdomain:7077.
Your output should look similar to the one below:
starting org.apache.spark.deploy.worker.Worker, logging to <PATH>/spark-3.1.2-bin-hadoop3.2/logs/spark-<USER>-org.apache.spark.deploy.worker.Worker-1-<HOSTNAME>.outRun sample pipeline with Spark Submit
Since Spark doesn’t support remote execution, we’ll be running one of the sample pipelines through Spark Submit.
INFO: the sample pipeline we’ll run in this example reads variables for file input and output from the Spark pipeline run configuration.
Check the variables tab for the Spark pipeline run configuration in the metadata perspective for more details.
The command below passes all the required information to run the samples input-process-output.hpl pipeline on our local Spark cluster with spark-submit.
bin/spark-submit \
--master spark://localhost.localdomain:7077 \
--class org.apache.hop.beam.run.MainBeam \
--driver-java-options '-DPROJECT_HOME=<PATH>/hop/config/projects/samples' \
/opt/spark/hop-fat-jar.jar \
<PATH>/hop/config/projects/samples/beam/pipelines/input-process-output.hpl \
/opt/spark/hop-metadata.json \
SparkTip: Optionally you can provide a 4th argument after the run configuration name: the name of the environment configuration file to use.
In this case, the fat jar and metadata export files were saved to /opt/spark. The last argument, Spark, is the name of the Spark pipeline run configuration in the samples project. Replace with the necessary arguments for your environment and run.
You should see verbose logging output similar to the output below:
23/10/08 08:52:35 WARN Utils: Your hostname, knowbi resolves to a loopback address: 127.0.0.1; using 192.168.86.44 instead (on interface wlan0)
23/10/08 08:52:35 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
>>>>>> Initializing Hop
Hop configuration file not found, not serializing: /opt/spark/spark-3.4.1-bin-hadoop3/config/hop-config.json
Argument 1 : Pipeline filename (.hpl) : /home/bart/projects/tech/hop/projects/hop-tests/code/beam/input-process-output.hpl
Argument 2 : Environment state filename: (.json) : /tmp/hop-metadata.json
Argument 3 : Pipeline run configuration : spark
>>>>>> Loading pipeline metadata
>>>>>> Building Apache Beam Pipeline...
>>>>>> Pipeline executing starting...
23/10/08 08:52:44 WARN S3FileSystem: You are using a deprecated file system for S3. Please migrate to module 'org.apache.beam:beam-sdks-java-io-amazon-web-services2'.
2023/10/08 08:52:45 - General - Created Apache Beam pipeline with name 'input-process-output'
2023/10/08 08:52:46 - General - Handled transform (INPUT) : Customers
2023/10/08 08:52:46 - General - Handled generic transform (TRANSFORM) : Only CA, gets data from 1 previous transform(s), targets=0, infos=0
2023/10/08 08:52:46 - General - Handled generic transform (TRANSFORM) : Limit fields, re-order, gets data from 1 previous transform(s), targets=0, infos=0
2023/10/08 08:52:46 - General - Handled transform (OUTPUT) : input-process-output, gets data from Limit fields, re-order
2023/10/08 08:52:46 - General - Executing this pipeline using the Beam Pipeline Engine with run configuration 'spark'
23/10/08 08:52:46 INFO SparkRunner: Executing pipeline using the SparkRunner.
23/10/08 08:52:47 INFO SparkContextFactory: Creating a brand new Spark Context.
23/10/08 08:52:47 INFO SparkContext: Running Spark version 3.4.1
23/10/08 08:52:47 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
23/10/08 08:52:47 INFO ResourceUtils: ==============================================================
23/10/08 08:52:47 INFO ResourceUtils: No custom resources configured for spark.driver.
23/10/08 08:52:47 INFO ResourceUtils: ==============================================================
23/10/08 08:52:47 INFO SparkContext: Submitted application: BeamSparkPipelineRunConfiguration
23/10/08 08:52:47 INFO ResourceProfile: Default ResourceProfile created, executor resources: Map(memory -> name: memory, amount: 1024, script: , vendor: , offHeap -> name: offHeap, amount: 0, script: , vendor: ), task resources: Map(cpus -> name: cpus, amount: 1.0)
23/10/08 08:52:47 INFO ResourceProfile: Limiting resource is cpu
23/10/08 08:52:47 INFO ResourceProfileManager: Added ResourceProfile id: 0
23/10/08 08:52:47 INFO SecurityManager: Changing view acls to: bart
23/10/08 08:52:47 INFO SecurityManager: Changing modify acls to: bart
23/10/08 08:52:47 INFO SecurityManager: Changing view acls groups to:
23/10/08 08:52:47 INFO SecurityManager: Changing modify acls groups to:
##
##
Lots of output omitted.
##
##
23/10/08 09:01:07 INFO MemoryStore: MemoryStore cleared
23/10/08 09:01:07 INFO BlockManager: BlockManager stopped
23/10/08 09:01:07 INFO BlockManagerMaster: BlockManagerMaster stopped
23/10/08 09:01:07 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
23/10/08 09:01:07 INFO SparkContext: Successfully stopped SparkContext
2023/10/08 09:01:07 - General - Beam pipeline execution has finished.
>>>>>> Execution finished...
23/10/08 09:01:07 INFO ShutdownHookManager: Shutdown hook called
23/10/08 09:01:07 INFO ShutdownHookManager: Deleting directory /tmp/spark-69bffb6a-90e2-415d-b4bc-63fcaf649999
23/10/08 09:01:07 INFO ShutdownHookManager: Deleting directory /tmp/spark-14f01b28-130c-48b4-93dc-49465cbb1392After your pipeline finishes and the spark-submit command ends, your Spark master ui will show a new entry in the 'Finished Applications' list. You can follow up any running applications in the 'Running Applications' and drill down into their execution details while running.