Running the Apache Beam samples With Apache Flink
Get Flink
Check the Supported Versions on the Getting Started With Beam page to find the latest supported Flink version for your Hop version.
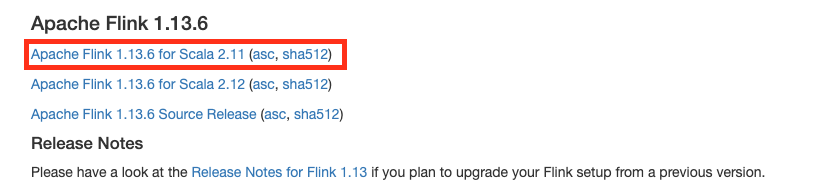
For example, for Hop 1.2, the latest currently supported version is 1.13. Make sure to download Flink for a recent and JDK 8 compatible Scale version. For Flink 1.3.6, this is Scala 2.11.
Download your selected Flink version and unzip to a convenient location.
Start your local Flink single node cluster
To keep things as simple as possible, we’ll run a local single node Flink cluster with a single command.
In the folder where you unzipped Flink to, run:
bin/start-cluster.sh
Your output should look similar to the one below:
Starting cluster.
Starting standalonesession daemon on host <HOSTNAME>.
Starting taskexecutor daemon on host <HOSTNAME>.The cluster shouldn’t take more than a couple of seconds to start. Once Flink is available, you’ll be able to access your Flink Dashboard at http://localhost:8081/
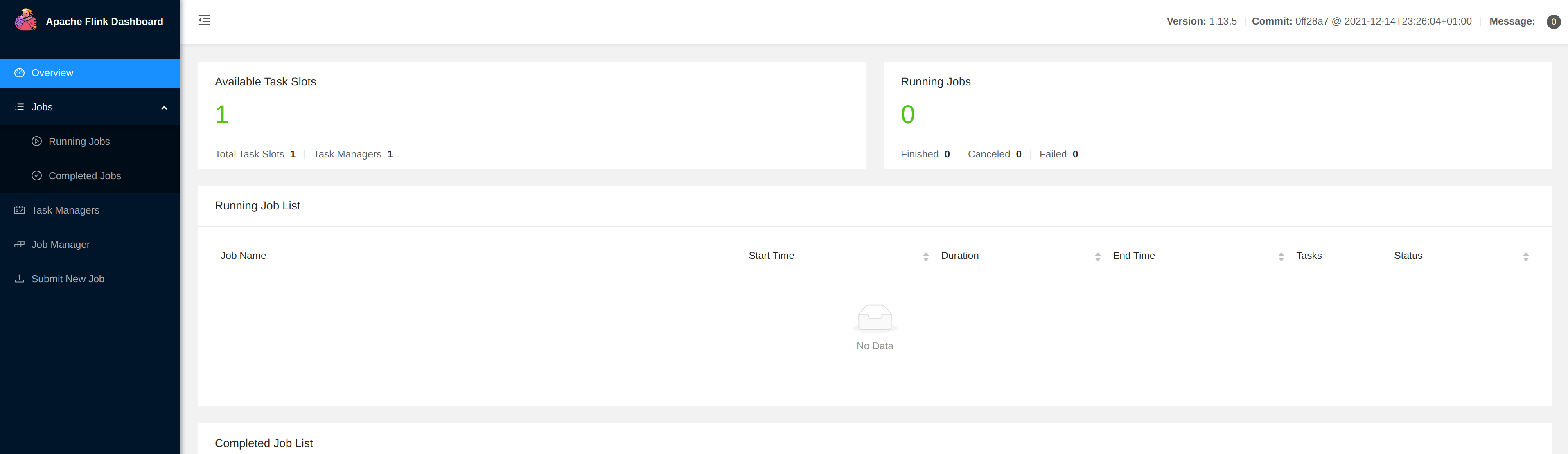
Flink Run Configuration setup
In Hop Gui’s metadata perspective for the Samples project, edit the Flink pipeline run configuration and make sure the Fat jar file location (the very last option) points to the Hop fat jar you created earlier in the prerequisites.

From Hop GUI
Running Hop pipelines on embedded Flink through Hop Gui will work just fine but is intended for testing purposes and won’t show in your Flink dashboard. You can leave the default Flink master to [local] to run the embedded Flink engine from Hop Gui. |
Set your Flink master to your cluster’s master. For embedded Flink, [local] will do.
Go back to the data orchestration perspective and run one of the Beam pipelines in the samples project. In this example, we used samples/beam/pipelines/generate-synthetic-data.hpl
When you start your pipeline from Hop Gui, it will appear in your Flink Dashboard.

From Flink Run
In a real-world setup, you’ll run your Flink pipelines from the Flink master through flink run.
Set your Flink master to [auto] and export your Hop metadata again (see prerequisites).
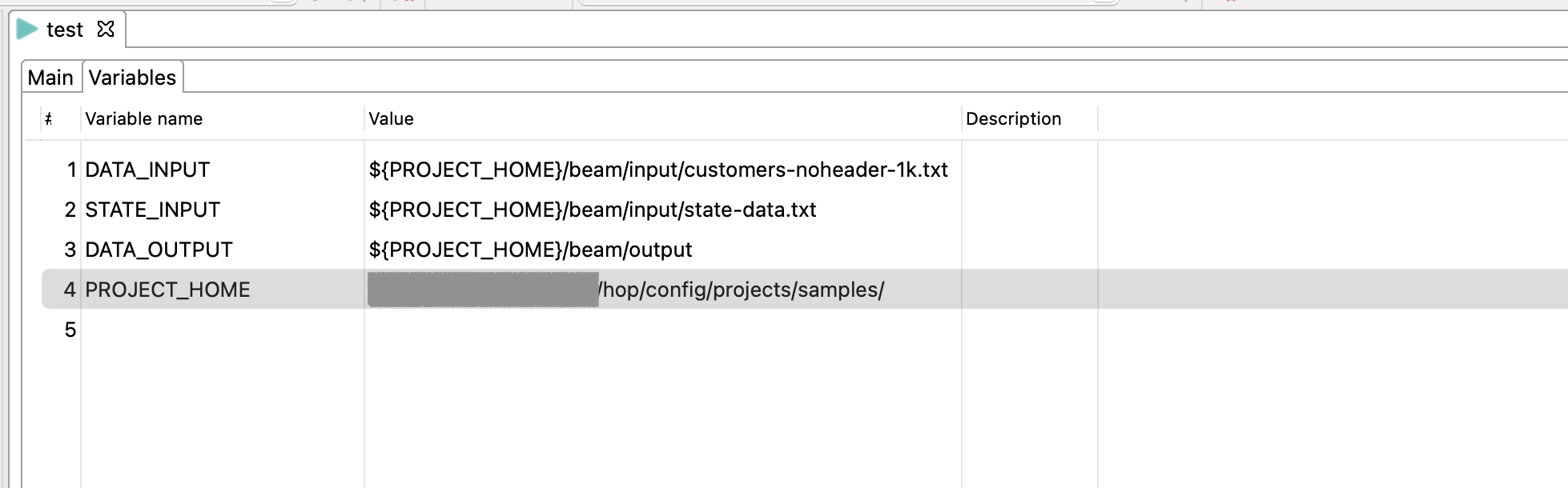
Unlike Spark you can not pass java options at runtime to the TaskManager. So we also want to set the PROJECT_HOME variable in the run configuration. This variable is used during execution to know where the source files are. (Metadata perspective → Pipeline Run Configuration → Flink → Variables) Alternatively, you can provide a 4th argument after the run configuration name: the name of the environment configuration file to use.
Use a command like the one below to pass all the information required by flink run.
bin/flink run \
--class org.apache.hop.beam.run.MainBeam \
--parallelism 2 \
/opt/flink/hop-fat-jar.jar \
<PATH>/hop/config/projects/samples/beam/pipelines/generate-synthetic-data.hpl \
/opt/flink/hop-metadata.json \
FlinkWith your Hop and Flink set up correctly, your output will look similar to what’s shown below:
Argument 1 : Pipeline filename (.hpl) : <YOUR_PATH>/hop/config/projects/samples/beam/pipelines/generate-synthetic-data.hpl
Argument 2 : Metadata filename (.json) : /opt/flink/hop-metadata.json
Argument 3 : Pipeline run configuration : Flink
>>>>>> Initializing Hop...
Hop configuration file not found, not serializing: <YOUR_FLINK_PATH>/flink/flink-1.13.5/config/hop-config.json
>>>>>> Loading pipeline metadata
>>>>>> Building Apache Beam Pipeline...
>>>>>> Found Beam Input transform plugin class loader
>>>>>> Pipeline executing starting...
2022/02/11 12:50:25 - General - Created Apache Beam pipeline with name 'generate-synthetic-data'
2022/02/11 12:50:26 - General - Handled transform (ROW GENERATOR) : 100M rows
2022/02/11 12:50:26 - General - Handled generic transform (TRANSFORM) : random data, gets data from 1 previous transform(s), targets=0, infos=0
2022/02/11 12:50:26 - General - Handled transform (OUTPUT) : generate-synthetic-data, gets data from random data
2022/02/11 12:50:26 - General - Executing this pipeline using the Beam Pipeline Engine with run configuration 'Flink'
Job has been submitted with JobID 83f34cefa8d061994b7028df2dcebfcd
Program execution finished
Job with JobID 83f34cefa8d061994b7028df2dcebfcd has finished.
Job Runtime: 129625 ms
Accumulator Results:
- __metricscontainers (org.apache.beam.runners.core.metrics.MetricsContainerStepMap): {
"metrics": {
"attempted": [{
"urn": "beam:metric:user:sum_int64:v1",
"type": "beam:metrics:sum_int64:v1",
"payload": "Ag==",
"labels": {
"NAMESPACE": "startBundle",
"NAME": "random data",
"PTRANSFORM": "random data/ParMultiDo(Transform)"
}
}, {
"urn": "beam:metric:user:sum_int64:v1",
"type": "beam:metrics:sum_int64:v1",
"payload": "oI0G",
"labels": {
"NAMESPACE": "read",
"NAME": "random data",
"PTRANSFORM": "random data/ParMultiDo(Transform)"
}
}, {
"urn": "beam:metric:user:sum_int64:v1",
"type": "beam:metrics:sum_int64:v1",
"payload": "Ag==",
"labels": {
"NAMESPACE": "init",
"NAME": "random data",
"PTRANSFORM": "random data/ParMultiDo(Transform)"
}
}, {
"urn": "beam:metric:user:sum_int64:v1",
"type": "beam:metrics:sum_int64:v1",
"payload": "oI0G",
"labels": {
"NAMESPACE": "written",
"NAME": "random data",
"PTRANSFORM": "random data/ParMultiDo(Transform)"
}
}, {
"urn": "beam:metric:user:sum_int64:v1",
"type": "beam:metrics:sum_int64:v1",
"payload": "oI0G",
"labels": {
"NAMESPACE": "output",
"NAME": "generate-synthetic-data",
"PTRANSFORM": "BeamOutputTransform/generate-synthetic-data/ParMultiDo(HopToString)"
}
}, {
"urn": "beam:metric:user:sum_int64:v1",
"type": "beam:metrics:sum_int64:v1",
"payload": "oI0G",
"labels": {
"NAMESPACE": "read",
"NAME": "generate-synthetic-data",
"PTRANSFORM": "BeamOutputTransform/generate-synthetic-data/ParMultiDo(HopToString)"
}
}]
}
}
2022/02/11 12:52:45 - General - Beam pipeline execution has finished.
>>>>>> Execution finished...After your pipeline finishes and the flink run command ends, your Flink dashboard will show a new entry in the 'Completed Job List'. You can follow up any running applications in the 'Running Job List' and drill down into their execution details while running.
