Best practices
Introduction
Apache Hop gives you a large amount of freedom when deciding how to do the things you want to do. This freedom means you can be creative and productive in arriving at the desired outcome. So please consider the advice given on this page as tips or free advice to be taken or rejected for a particular situation. Only you can decide what the advice is worth.
Naming
Transforms and actions
When looking at a pipeline or workflow it’s so much easier to see what’s going on if you give meaningful names to the transforms and workflows.
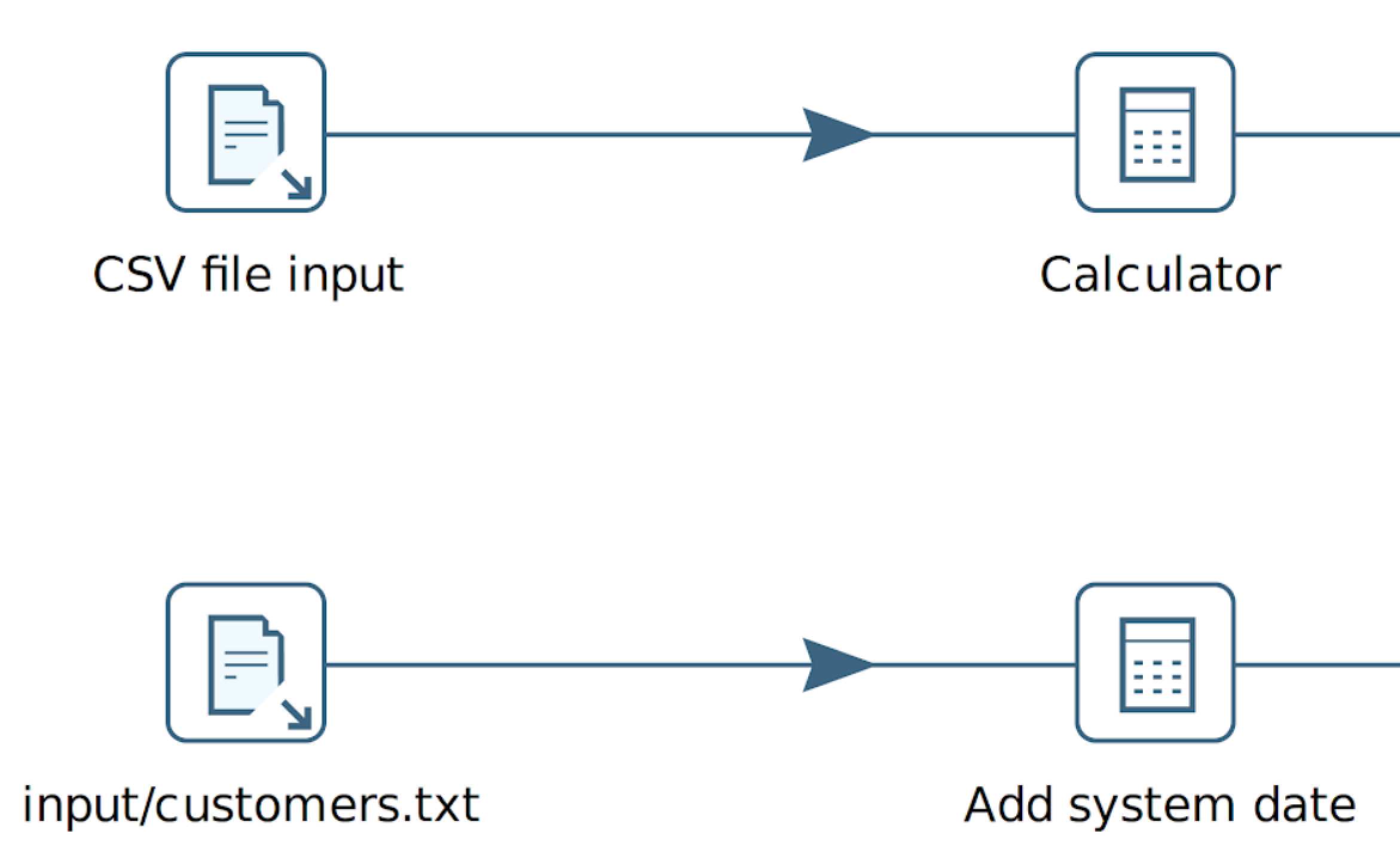
For input and output files, why not use the filename you’re using?
| You can use any unicode character in the name of a transform or action and even newlines are allowed. |
Metadata
When giving names to metadata objects like relational database connections, avoid environment specific words like a country, region, lifecycle environments:
Here are some examples to avoid and possible alternatives:
-
Test Database → CRM
-
France MySQL → WWW
-
East Coast Cluster → Fraud
Naming standard
What you can see in larger projects is that projects can become quite cluttered after a while. Here is some advice on how to keep things tidy and clean…
-
Folders can have sub-folders: organize your work with sub-folders in a project. It’s just hard to work with hundreds of pipelines and workflows in a single folder.
-
Use a naming convention for any object that you need to give a name: pipelines, workflows, folders, names, tables, fields, …
-
For larger projects you should consider setting up a naming standard. It’s just a document in which you specify how you want to name things.
-
Make sure to adjust, verify and enforce your naming standard periodically. If you don’t plan to do this you might was well not set up a corporate standard.
-
Consider scripts and commit hooks or a nightly run on your build server (Jenkins) to validate your naming standard.
Size matters
Limit the amount of transforms or actions!
-
Larger pipelines or workflows become harder to debug and develop against.
-
For every transform you add to a pipeline you start at least one new thread at runtime. You could be slowing down significantly simply by having hundreds of threads for hundreds of transforms.
If you find that you need to split up a pipeline you can write intermediate data to a temporary file using the Serialize to file transform. The next pipeline in a workflow can then pick up the data again with the De-serialize from file transform. While obviously you can also use a database or use another file type to do the same, these transforms will perform the fastest.
Variables
Variables provide an easy way to avoid hard-coding all sorts of things in your system, environment or project. Here is some best practices advice on the subject:
-
Put environment specific settings in an environment (Duh!) configuration file. Create an environment for this.
-
When referencing file locations, prefer
${PROJECT_HOME}over expressions like${Internal.Entry.Current.Directory}or${Internal.Pipeline.Filename.Directory} -
Configure transform copies with variables to allow for easy transition between differently sized environments.
Logging
Take some time to capture the logging of your workflows and pipelines. Any time you run anything you want to have a trace of it. Things tend to go wrong when you least expect it and at that point you like being able to see what happened. See Logging Basics, Logging Reflection or consider logging to a Neo4j graph database. This last one allows you to browse the logging results in the Neo4j perspective.
Mappings
If you have recurring logic in various pipelines, consider writing Mapping. It is a pipeline reading from a Mapping Input and writing to a Mapping Output transform. You can re-use the work in other pipelines using the Simple Mapping transform.
Metadata Injection
If you find that you need to create 'almost' the same pipeline a lot of times, consider that you can use Metadata Injection to create re-usable template pipelines.
-
Avoid manual population of dialogs
-
Whenever you need dynamic ETL
-
Supports data streaming
Example use cases include: * Load 50 different file formats into a database with one pipeline template * Automatically normalize and load property sets
Performance basics
Here are a few things to consider when looking at performance in a pipeline:
-
Pipelines are networks. The speed of the network is limited by the slowest transform in it.
-
Slow transforms are indicated when running in Hop GUI. You’ll see a dotted line around the slow transforms.
-
Adding more copies and increasing parallelism is not always beneficial, but it can be. The proof of that pudding is in the eating so take note of execution times and see if you should increase or decrease parallelism to help performance.
Governance
Here are some self-evident pieces of advice:
-
Version control your project folder. Please consider using git.
-
Reference cases in commits
-
Make sure to have backups
-
Run continuous integration
-
Set up lifecycle environments (development, test, acceptance, production) as needed
-
Test your pipelines with unit tests
-
Run all unit tests regularly
-
Validate the results & take action if needed
Loops
Avoid looping in workflows. The easiest way to loop over a set of values, rows, files, … is to use an Executor transform.
-
Pipeline Executor : run a pipeline for each input row
-
Workflow Executor : run a workflow for each input row
You can nicely map field values to parameters of the pipeline or workflow making loops a breeze.